| By | Casey Muratori |
Corn Rows
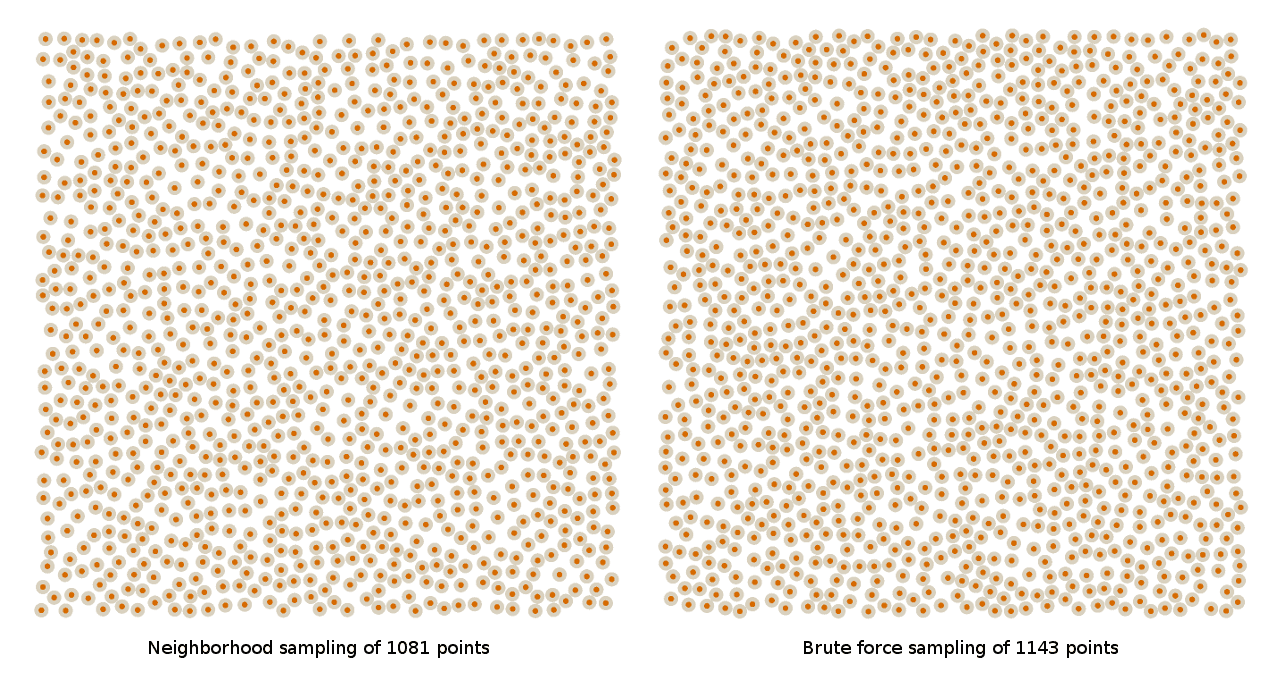
Here are some screenshots of the patterns produced by the original brute force and the neighborhood sampling techniques I talked about last time:
Here’s what these patterns look like from a typical player perspective:
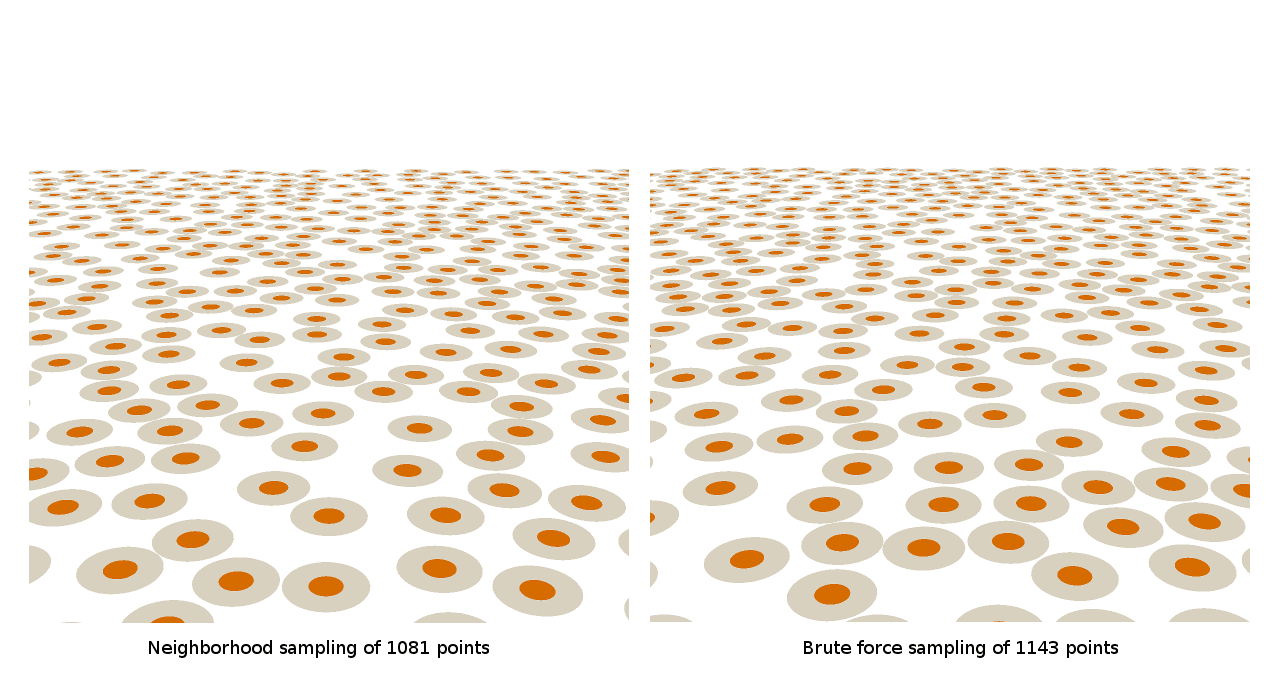
Finally, here’s what the patterns look like when there’s a set of ground flora billboards placed on each one:

As you can see, there’s not a lot of difference between the two, so, good job us, we did a reasonable job last week matching the brute force algorithm so it could run fast enough to be effective in The Witness. But if you look at these screenshots for a while, you can see that it’s a bit difficult to tell how good the blue noise is in general. In fact, at first, I really had no idea how good or bad these patterns were. I had no real baseline to which I could compare images like these. Without some known scheme that produces better results, who’s to say how good this pattern is?
Intuitively, it did look to me like the blue noise covered the space fairly effectively. At a high level, the grass distribution problem could be stated as “use the fewest number of points to produce a visually pleasing covering of a specified area”. I say “fewest number of points” because, as with any real-time rendering problem, the fewer the number of points used to adequately cover the space visually, the less cost there is to rendering the grass every frame. The less cost, the more graphics horsepower there is to render other things. And The Witness has plenty of other things that need rendering every frame, believe me.
So, yes, if I was concerned about the patchiness in some places, I could always increase the density of the blue noise, spending more rendering budget but getting very dense coverage:

But obviously I want to keep the density as low as I can and still have reasonable coverage, so I felt like the appropriate level was probably something like first set of shots. Without using excessively many points, you can’t possibly prevent gaps very near to the player, but a little ways out, an ideal pattern would make the grass look nice and full.
However, as I played with patterns like this one last week, I began to notice something very unfortunate. In that same pattern, if you move the camera to certain places, parts of the pattern form nearly colinear rows, such that a noticeable gap is visible even relatively far from the camera, where ideally there should have been enough overlapping grass to look solid:

This was present in both techniques, so it seemed to be a property of blue noise in general, or at least any sort of blue noise generated via the poisson disk method.
For reasons I won’t go into at the moment, I’ve had to spend some time sitting in the back seat of a car in Nebraska while it drove down the world’s most boring highway, which as far as I can tell is every highway in Nebraska. If you look out the window at the cornfields while you drive by, you’ll notice that the rows of corn have exactly this same properly: from many angles, they just look like a field of corn, but as you hit just the right angle, they suddenly look very regular and you can see the long, narrow gap between rows. Fine for a cornfield, but not so good if you’re trying to give the illusion of dense coverage.
Due to its resemblance of this cornfield property, I took to calling the problem with blue noise “The Nebraska Problem”.
I didn’t like having the Nebraska problem in my grass distribution any more than I liked having to ride around Nebraska. As I alluded to last week, it’s a theoretical problem because as far as I know, there’s nothing inherently wrong with these blue noise algorithms that causes this occurrence. There’s nothing wrong with our practice, in this case. It’s our theory that is apparently inadequate.
Since I did not know of any noise theory that purported to address this problem, nor even any papers that mention it existing, I decided to experiment with breaking the rules of blue noise to see if I could solve the Nebraska problem myself.
Playing with the Packing Ratio
As is the case whenever I start tackling a new problem, I didn’t really have my bearings yet. I could see that there was this problem, but I hadn’t really specifically defined it yet, so I randomly tried some obvious things.
The first thing I tried was changing how the neighborhood algorithm chose its points. Last week, since the article was quite long, I didn’t go into detail about how the neighborhood algorithm specifically chooses points to try. I simply said to pick a random point “between r and 2r” away from the base point in a random direction.
But there’s a number of ways that you could do this. The most straightforward would be to uniformly pick an angle and distance between r and 2r, and use them directly. But if you plot points chosen this way, you will find that they have a very distinct bias toward the center of the circle:
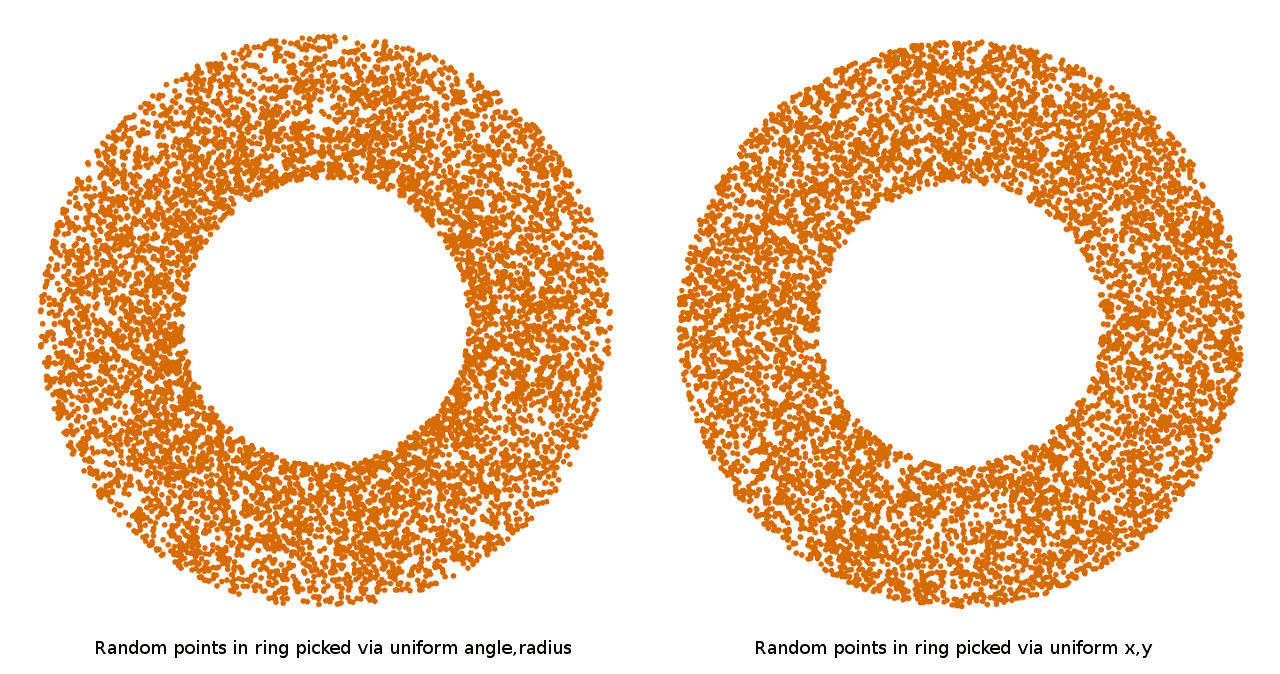
What’s going on here? Well, if you think about it, the larger the radius of a circle, the further a point on the circle moves as the angle changes. This means that, to cover the circumference of large circles with the same euclidean density of random points, you’d have to pick more random angles than if you were covering small ones. So, if you uniformly pick a random angle and a random radius, you will always end up covering the smaller radii more densely than the larger radii. To actually pick uniformly dense points inside a circle, you have to either pick the angle and radius non-uniformly, to account for the changing effect of the angle as the radius grows, or more simply, you can just pick points uniformly in a square and throw out ones that lie outside the circle.
OK, why am I bringing this up? Well, when I implement the neighborhood algorithm, I typically leave in the bias toward the center. It’s faster this way, and I find that it doesn’t actually affect the output pattern in any visible way. But, since my goal now was to modify the pattern, I got to thinking, what if I force the selection of points to be even more biased than it already was?
So I tried introducing the concept of a “packing ratio”. Instead of picking points between r and 2r away from the base point, I made the 2 a parameter. This way, I could force all the chosen points to be closer to their base points, theoretically shrinking the average distance of the pattern and producing a tighter packing:

Unfortunately, this quickly proved to be fruitless, as packing more tightly only exacerbated the Nebraska problem. If you look at the patterns, you can see why: As the packing becomes tighter, the chances become greater that two “branches” of the neighborhood algorithm will run parallel to each other, without the opportunity to create more stochastic patterns that would break up the empty space in between.
Targeting Gaps
So playing with the packing was counter-productive, and it makes sense why. I started to think, well, maybe all I really need is to allow points to be placed more flexibly into spaces that aren’t densely covered. Maybe if I do a second pass over the initial blue noise pattern with a more permissive placement radius, I can just “fill in” the places where aligning rows created visible gaps:

It turns out this actually works, or so it seems at first. But when I checked the point count, I realized that if I had simply generated a blue noise pattern with the same number of points as I ended up with after gap filling, it, too, was dense enough to not evince the problem:

So, while targeting the gaps in the initial pattern might be fruitful, it didn’t seem immediately obvious how that could ever work effectively given that it would end up proliferating the number of points rather than fixing the problem with the distribution of the existing points.
Planting Along Lines
Having failed at a few blue noise modifications, I started to try more ridiculous approaches that had no blue noise properties at all, just to see if anything stuck. Going back to first principles, I thought, well, if my goal is to prevent lines of sight where there are gaps, maybe I should just generate the pattern based on that. So I wrote an algorithm which picked random lines of sight across the region. It would step along each line and look for lengths of the line that went a certain distance without encountering a point:

Unfortunately, because the algorithm picks random lines, there’s really no reason why it can’t sometimes pick two lines right next to each other, which leads right back to the Nebraska problem. In some parts of the pattern, it works just fine, but in those parts where lines happen to be roughly parallel early on in the process, the Nebraska problem ran rampant.
Selective Removal
Along the same lines (pun intended) as the previous method, I thought perhaps I could try the reverse approach: start with a dense covering of the region, generated by white noise, and then remove only those points which I could verify did not create long continuous lines of empty space. For each point, I would check a large number of directions, and see where the first “hit” along those lines was, backwards and forwards. If the distance was small enough along all lines I checked, I would remove the point. If the resulting distance along any of the lines would have been too great, I would leave the point:

Unfortunately, this yielded similar results to the previous attempt: tune the parameters one way, no Nebraska problem, but the sampling was too dense. Tune them another way, and the sampling was too sparse and you get visible gaps everywhere, even if you happened to avoid the Nebraska problem specifically.
At this point, I probably should have realized what was going on, but I didn’t. Bear in mind that this is probably midday Wednesday, and I’m realizing I’m never going to make my Witness Wednesday deadline, so I’m starting to freak out a little bit. I’m not thinking as clearly as I should be. What do I do? Do I press forward, or do I call it and say, “Well, there’s a problem with this algorithm, but I’ll be damned if I know how to solve it. Have a great Wednesday. CHRISTMAS IS CANCELED!”
I know how important Santa Claus is to all of you. It’s not every day that an obese, elderly, perpetually smiling bearded man surreptitiously enters your house without permission and leaves “presents” for your children whom he has been “watching” all year. Do I really want to be the person who cancels Christmas? Do I want to be that guy?
No, of course not, so I decide no, Christmas cannot be canceled. Christmas isn’t canceled. CHRISTMAS IS MERELY DELAYED…
Relaxation
OK, it’s fine, no problem, Christmas is delayed. It was on a Wednesday, now it’s on a Thursday. Or a Friday. Back to work.
Now, if you’ve read a lot of graphics research papers, I think you’ll agree with me when I say, whenever people reach a place in an algorithm where it just plain doesn’t work, relaxation is the go-to fix. Can’t get those points quite where you need them? Relax! If you can’t come up with a way to put the points where they need to be, let the points figure it out themselves.
So I added a relaxation step. And I tried two different “energy functions” for the relaxation, the first being a standard “repel other points” version:

And the second being a “break up contiguous lines version”, which looked for sets of three or more points which lay roughly in a line and tried to move one of the interior points toward whichever side appeared to have more open space:

As you can see from the images, neither of these relaxation strategies seemed to show any promise. Although they were both completely ad hoc and could be tuned for much better results, I didn’t see anything in the preliminary results that indicated to me there’d be much benefit to a relaxation strategy. It seemed that no matter how I tried to move the points, they’d always end up accidentally forming new corn rows even if I was breaking up old ones, or spacing themselves out too much and forming non-Nebraska gaps, which are even worse.
At this point it was Wednesday night, and it was time for dinner. But as it happened, it was not just any old Wednesday, so it would not be just any old dinner. In fact, it was a Wild Wednesday, which meant it was time for a Wild Wednesday dinner…
Directional Constraints
Wild Wednesday is a very special type of day (often not on actual Wednesdays, for reasons I will leave unexplained) where Sean Barrett, Fabian Giesen, Jeff Roberts, and myself get together for some absolutely crazy wild times. Imagine one of those “Gone Wild” videos that they film at Spring Break in Florida, only instead of Florida, it’s Seattle, and instead of a bunch of inebriated college kids, it’s four programmers sitting around a restaurant table for an hour discussing the minutia of a particular technical issue. And if all that doesn’t sound wild enough for you, this particular Wild Wednesday even had a special guest, Tommy Refenes, so I knew it would be even more Wild than normal.
Going to Wild Wednesday will be helpful, I thought to myself, because I can discuss the problem with the Wild Wednesday crowd, and maybe get some fresh perspective. Which I do.
After I explained the problem to them, both Fabian and Sean came to the conclusion that the best thing to do would be to try to prevent the original neighborhood algorithm from producing lines in the first place, thereby avoiding the problem of having to fix the pattern after the fact. If the initial random generation didn’t produce rows, this might yield better patterns than trying to fix the rows afterward, because fixing the rows afterward is a global problem — it requires pushing points around in ways that might imply large changes in the pattern to accommodate the movement. If you never generate rows in the first place, then the whole pattern will be adapted to be rowless, thereby getting that global consideration for free.
So I tried some heuristics to prevent lines, such as ensuring that each new point would never be along the same line as the previous point:
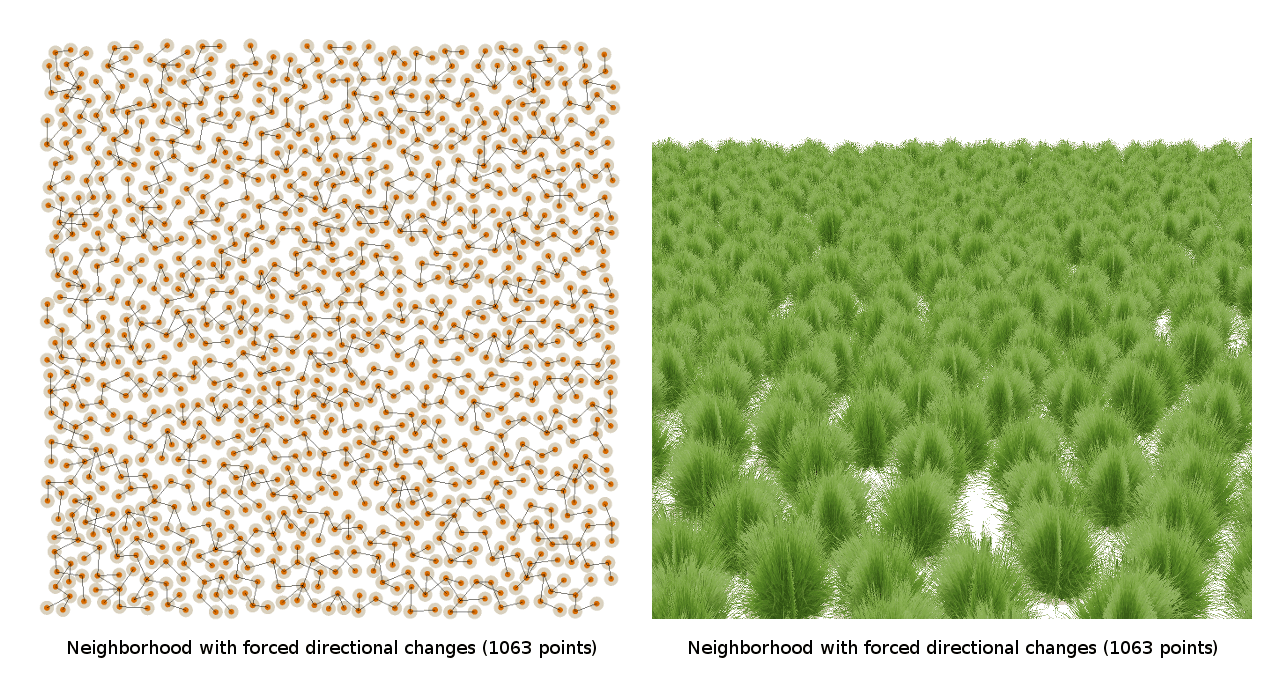
Unfortunately, you still get the Nebraska problem. Even though no direct branch of the neighborhood algorithm produces rows, nearby branches seem to conspire to produce rows all the same!
This was starting to get ridiculous. How is it that every single algorithm produces the same artifact? What is going on here?
Curved Hexagonal Packing
Although I still hadn’t quite arrived at the key insight yet, I started to realize what was wrong. I took a step back, and really thought about what would be necessary to produce a pattern that had no corn rows, but also didn’t use excessively many points. I started coming to the conclusion that what you really want are curves. You want to guarantee that anything you generate is always going to have nice curves to the points, because two curved rows of points is the one pattern that you know will never show linear gaps. Anything that’s random, really, might produce some confluence of points that forms neighboring lines, even if its only for three points on either side — enough to cause the Nebraska problem. So the thing that produces a guaranteed lack of gaps probably isn’t random at all, it’s probably regular.
This totally changed my thinking about the problem. The whole time, I’d been thinking that randomness was an asset to creating a good covering. But now it seemed like, if you really think about the problem, randomness may actually be bad.
So I started to think about regular patterns that might have the properties I wanted. It needed to not look obviously regular when viewed from the typical player’s perspective (standing among the grass). It needed to never have continuous straight lines of points. It needed to efficiently cover the space.
I knew that hexagonal packings were the densest possible packings for circles:

So I figured, well, if you’re going to efficiently cover the space, then a hexagonal packing is probably the best thing to start with, because it could keep each point at exactly the distance that would be visually optimal for coverage while minimizing the number of points used.
But hexagonal packings are obviously terrible by themselves, because they have cornrows in several directions, which is the opposite of what I wanted. So I thought, well, what if I bent the hexagonal packing? I tried interpreting the hexagonal packing in polar coordinates, to give the rows a bent shape

I also tried various rotational schemes, similar to the original neighborhood algorithm where I would branch out to new points in a hexagonal pattern that was rotated either randomly or consistently.
Unfortunately, the hexagonal packings didn’t seem to be working. Either they left gaps, produced clumps, or made lines in one direction or another. But thankfully, that’s when it finally dawned on me what the actual objective was.
See, this distribution is in a plane. There are always two orthogonal bases to a plane. So ensuring one axis of curvature, as I was doing by trying to curve the hexagonal packing with polar coordinates, was never going to work: I’d warped one of the axes along which lines could form, but not the other. What I needed was a distribution of points with two axes of curvature, so that there would literally be no way to form lines through the space at any periodicity at all.
Staggered Concentric Intersection Packing
OK, two axes of curvature, no problem. I’ll just take two circles, and I’ll place the points of my pattern where concentric rings of those circles intersect:

This was looking good. I felt like I might be close. Looking at the distribution from a variety of angles, the main problem was just that the curvature was still visible, since it was a bit too subtle to completely visually obscure the space between points. I thought about trying to increase the curvature, but then I thought, well, what if I just staggered every, say, third concentric circle ring? Instead of evenly spaced concentric rings, every third ring I’d offset the radius a little bit to add some apparent jitter, helping the gaps, but also reducing the apparent regularity of the pattern a bit in the process. Mind you, it’s a completely deterministic offset, so there’s no real randomness:

Bingo. This covering was exactly what I had been looking for! Dense visible coverage, and absolutely no way to see gaps anywhere except right where you’re standing (which, of course, is not fixable by any pattern that doesn’t use a huge number of points and literally cover the space completely). The pathological viewpoints from the unstaggered case were completely fixed:

And the bonus surprise? It can use significantly less points than I’d been using for the gappy blue noise while still producing better visual coverage:

Why Such Abundant Failure?
As with most tricky problems, when you’re in the thick of it, you often can’t see the right way to look at things. That’s usually why you’re in the thick of it and not… uh, in the thin of it? Whatever the opposite is. Either way, looking back over the past few days, with the benefit of hindsight I can see the fundamental mistake in my approach.
I had started with a pretty good random covering, blue noise, and had wanted to improve upon it. But if you think about what randomness is and how it works, you realize a rather obvious truth: randomness is never optimal. For any set of criteria, the chances that you will pick a set of optimal inputs in a randomized way, no matter how you constrain them, are extremely low. If you take 100 dice and roll them, you won’t roll 600. Probably ever (unless they’re d20’s, but I’m trying to keep these metaphors accessible to non-D&D people). You can’t constraint your way out of it, either. Even if you take all the dice and change the 1’s, 2’s, 3’s, and 4’s to 6’s, so that there’s literally just 5’s and 6’s on the dice, you will still almost never roll 600. Even if you did that then took all the 5’s and re-rolled them, you could even do that seven times before you got all 6’s.
So when you have it in your head that you want to try to make something optimal, chances are, you’re going to have to look beyond randomized algorithms. I kept looking for schemes that would produce optimality out of randomness, but that’s simply too unlikely. Because blue noise is a pretty good random pattern for my purposes, I was dancing around the breaking point of randomness, and every scheme I tried was destined for failure, because there simply was no better random scheme. In order to make that leap, I had to switch from chaos to order, and drive at the optimum directly.
This is really the crucial insight to take away from this experience. The pattern itself is not so important. What’s important is to know whether the thing you’re trying to accomplish is about optimization, and if it is, do you need randomness for other reasons? If you do, you will need to plan on hitting something less than optimal. If you don’t, you may well need to jettison the randomness in order to make progress.
As with most realizations, it’s very straightforward when you think about it, and almost explains itself. But it often takes an actual experience with it to make it sink into your brain in a way that will let you instinctively reason about it and think to apply it to new circumstances where it can be useful.
The Worm-Catching Ninja
So what have we learned, coding ninjas? Well, I think we’ve learned that, as the saying goes, “the persistent ninja always catches the worm”. If that saying doesn’t sound familiar to you, it’s probably because you’re not as well versed as I am in historical Japanese literature. It’s OK. Summer’s just around the corner, and you can put The Cambridge History of Japan on your summer reading list.
In the case of this particular worm-catching ninja, I suppose this pattern situation was a bit of an obsession. It’s not clear to me that the new pattern is at all necessary to employ in games, nor am I sure it’s worth it to go back and put it into The Witness, due to the potential complexity of making it work with all the other grass planting features (more on that next week). But as I explained in the previous section, I learned a lot from this experience, as I invariably do when I set out to solve a technical problem and refuse to take “noh” for an answer (continuing on the ninja theme, Noh is a traditional form of Japanese theater that is incredibly long and supposedly quite boring, but I’m sure most ninjas of class and distinction would have partaken from time to time).
So for me, working on problems like this is rarely about whether or not I really need the solution. I knew going into it that blue noise was “good enough”. But if I have an inkling that there is a “better” lurking behind the “good enough”, I usually find it’s worth it to push. In this case, I’m very glad I did, because it opened up a new way of thinking about patterns for me, and I strongly suspect that, even if I don’t use this particular pattern in the future, my deeper appreciation for regular vs. randomized approaches in general will likely pay dividends in a number of other contexts.
That’s it for this Witness Wednesday. Come back next week for a look at the various other features I implemented in The Witness grass planting system, complete with a surprise video, narrated by none other than your esteemed author!