| By | Casey Muratori |
Walkmonster in Wall
In the context of The Witness, the goal of player movement code is to be as unobtrusive as possible. The player is supposed to fully immerse themselves in an alternate reality, and every last detail is important to this experience. The last thing you ever want to happen is to have the player notice the fact that they’re sitting at a computer asking it to move a virtual viewpoint around.
For that reason, the player movement code has to be rock solid. If you can get stuck on edges, trapped in walls, fall through the floor, walk through a cliff, walk down a hill but not back up it, etc., it immediately breaks the immersion and reminds you that you are playing an artificial experience mitigated by an unreliable system. It can also lead to disastrous consequences for the player in some circumstances if there’s no way for them to recover from the problem with restarting or reloading a (possibly very old) save game. If you play games often, you’ve probably encountered one or more of these problems in shipping titles, and you know what I’m talking about.
Last week I began to work on this problem. I decided the first thing to do was to write a few integrated tools for working with the player movement code so we could analyze it and see how it was currently behaving. Immediately, when I opened up the project, I found myself with a familiar conundrum: what to name my first source file. This is always the most important part of any project (as Bob Pollard once said of band names and album names). If you have the right name for your source file, it’s smooth sailing from there. Pick the wrong name, and you might as well call the project off.
But what to call a system for bulletproofing player movement code? I’d never been asked to write code for that before. When I thought about it, I realized that I’d only personally seen evidence of similar code once before: when playing an early beta of Quake. There were some bugs with the monster placement, and in the console window, you could see error messages announcing the fact that the monsters, instead of spawning on the ground, had spawned partially intersecting with the level geometry. Each debug message began with the phrase “walkmonster in wall at…”
Bingo. It’s hard to ask for a better source file name than “walk_monster.cpp”. I was pretty sure, from that point forward, the code was going to come along nicely.
Drive Toward Point
When you’re trying to test a system, the most important thing to do is actually test the system. Even though that sounds like a straightforward rule, people writing tests often fail to observe it.
In this specific case, there are very easy ways to think that you were testing the player movement code without actually testing it. One example would be to do some kind of analysis on the collision volumes and walkable surfaces in the game, looking for small areas, gaps, etc. Once you’d eliminated all of these, you’d then proclaim the world safe to traverse and move on.
But this is testing the data, not the actual code. It’s still easily possible to have bugs in the movement code that result in bad behavior even with sanitized data.
To avoid this kind of trap, I wanted the testing system to remain as close as possible to what a human does to actually control player movement in the game. I started out by writing two routines to serve as the building blocks of this kind of testing.
The first is the closest to real human usage. It’s an update call that hooks into The Witness’s input processing and feeds it synthetic mouse and keyboard events. It can do some basic things that humans might do, such as looking around, walking toward a point, looking toward a point, and so on. It does these through nothing but emulation of human interaction with the mouse and keyboard, so I know that everything in The Witness’s input path will be running as it actually would during testing. I’ll talk more about this system and how it’s used in later installments.
The second piece of code is one step removed from that level. It’s a function called DriveTowardPoint that takes two points in the world and, calling the existing player collision system, attempts to move cleanly from one to the other. When it returns, it provides information about the attempt such as obstacles encountered and whether or not the destination was successfully reached.
This function is not quite as reliable as the synthetic input method of testing, because it eliminates a portion of the actual player movement system from testing. For example, any erroneous state associated with where the player is that the collision system might have built up won’t affect tests using this function. Nevertheless, I felt it valuable to have this level of testing available because it can much more rapidly test large areas, since it does not require the entire game loop to run, and thus can be employed much more frequently and over the entire world instead of just isolated test runs.
It’s also worth noting that there are no physics inputs to this function; there are no velocities specified for the starting point, for example. This is because The Witness is not an action game, so there are few stateful physical properties for the player. Players can’t jump, they can’t wall-run, they can’t enter bullet-time. Supporting these types of behaviors is possible with systems of the kind I’ll be discussing, but they add a layer of complexity that we don’t have to worry about on this project.
Anyhow, with DriveTowardPoint in place, it was possible for me to start on my first goal for the system: determining everywhere the player can go on the island of The Witness.
Rapidly Exploring Random Trees
Where can the player go? It seems like a simple question, but you’d be surprised how many games ship without the development team knowing the real answer. If possible, I want The Witness to be one of the few games where the team knows prior to shipping exactly where the player can and can’t go, no surprises.
This makes the problem statement, but perhaps not the problem, very simple: given a DriveTowardPoint function that faithfully determines whether a player could move in a straight line between two points, produce a coverage map showing everywhere the player could end up.
For reasons that I can’t necessarily explain, I had in my head, even before writing a line of code, that the best way to do this would be to use a Rapidly Exploring Random Tree. For those of you unfamiliar with this algorithm, it’s a very simple process whereby you record all the points you’ve visited along with a reference to the point from which you walked there. To add points to the tree, you pick a random target point anywhere in the world, select the closest point in your tree thus far, and try to get from that tree point to the target point. Wherever you end up, that’s a new sample point.
Normally, this is more of a pathfinding algorithm, so interleaved with random points, you repeatedly select some goal point as a target. This biases the exploration of the space toward the target, which is what you want when your only aim is to reach the goal. But in this case, I wanted to produce a complete map of everywhere the player could go, so I was exclusively using random samples.
After implementing this (it is thankfully a very simple algorithm to write, so it doesn’t take long), I could see that it did do a reasonable job of exploring the space (the white etchings show paths that have been explored, and the red vertical lines show places where an obstacle was hit):

However, once I actually looked at how it behaved, it was clear to me that it wasn’t really the algorithm I wanted. For example, even after many iterations, it often barely explores rooms like this one, despite densely covering the area just outside, simply because it doesn’t pick enough random targets inside it:

If I’d thought about it before I started, I would have realized that the benefit of something like a Rapidly Exploring Random Tree is that it explores high-dimensional spaces efficiently. In fact that’s the primary reason you normally use it. But in The Witness, we don’t have a high-dimensional space. We have a two-dimensional space (distributed on an intricate manifold, yes, but a two-dimensional space nonetheless).
In this low-dimensional space, the benefits of a Rapidly Exploring Random Tree are muted, and the drawback is critically bad for my stated purpose: it’s designed to most efficiently find ways to connect pairs of points in a space, not to efficiently find all reachable points in that space. If you care about the latter, then Rapidly Exploring Random Trees will actually take an excruciatingly long time to do so.
So, I quickly realized that what I should be looking for is an algorithm that efficiently covers low-dimensional spaces in their entirety.
3D Flood Filling
Once I actually thought about the choice of algorithm, it seemed obvious that what I actually wanted was something like the old 2D flood fills we used to use to fill regions of a bitmap. Given a starting point, I just wanted to fill up the entire space, exhaustively probing every possible way you could go. Unfortunately, this is a lot less straightforward in the world of The Witness than it is in a 2D bitmap, for a number of reasons.
First, there’s no clear concept of finite connectivity around a point. Everything is continuous. It’s not like pixels where you can easily enumerate 4 possible places to go from every given location, and check each one in turn.
Second, there’s no fixed size for a locus in space like there is for a pixel in a bitmap. Walkable surfaces and obstacles can be anywhere, they have no minimum or maximum feature size, and no alignment to any external grid.
Third, although walking around in The Witness locally acts as if it were on a plane, the space itself actually is a deeply interconnected and varying manifold, with walkable regions directly above other regions (stacked perhaps several times over), and special connectivity that changes based on world states (such as doors that open, elevators that go up and down, etc.
Given these complexities, it is very easy to think you have devised a way to do a flood fill, only to find after you’ve implemented it that it gets bogged down oversampling areas, misses important paths, produces erroneous connectivity information at places where the manifold is complex, or is simply too cumbersome to use because it must be restarted to cope with changes in the world state.
No good solution to all of this immediately came to mind, so I tried some simple experimentation. Using the Rapidly Exploring Random Tree code I had written, I changed the target point selection from random selection to a very controlled selection. Each time a new point was added to the tree, I would say that points a unit step along the cardinal directions from that point where to be considered future targets, just like a basic 2D flood fill.
But of course, this would produce a useless sampling loop if I wasn’t careful. A point would branch out to a neighborhood of 8 points around it, but those 8 points would all then want to try the original point again, and this would go back and forth forever. So in addition to the controlled target selection, I also needed the simple constraint that any target which wasn’t some minimum useful distance away from an existing target point would not be considered. To my surprise, these two rather simple rules did produce a somewhat usable flood fill:

Not bad for just trying the obvious thing. But it suffers from what I’ve taken to calling “boundary echo”. You can see this effect in the following screenshot, taken while the map exploration was still in progress:

In regions with no obstacles, this algorithm proceeds nicely, sampling at a relatively even distance. But once it hits a boundary, the intersections there produce points that are “off grid”, in that they are not aligned along the sampling pattern with which the algorithm filled the adjacent open region. The reason “on grid” points don’t produce overly dense tessellation is because any new point that tries to step back onto one of the previous points finds the previous point there and declines to reconsider it. But when new points are produced on the boundary, they are completely unaligned, so there is nothing to stop them from stepping back into the already explored space. This creates a wave of offset sampling which will continue until it runs into a fortuitous line of points somewhere else that happen to be close enough to its advancing front for it to consider them coincident.
Although this may not seem like a huge problem, it is actually critical. The entire goal of an algorithm like this is to concentrate the samples in the areas where they are most likely to yield productive results. The more time you spend sampling and resampling wide open regions, the less time you spend mapping the actual edges of that region, which is the information you actually wanted. Because this is a continuous space and only an infinite number of samples can truly reveal its exact shape, your ratio of meaningful to meaningless samples is literally the measure of how effective your algorithm is at producing the walkable area.
Now, there is an easy fix for this specific problem: expand the distance at which two points are considered “close enough”. But by doing this to reduce sampling density in places you don’t care about, you lose sampling density in places you do care about, like around boundaries where you are trying to carefully probe for holes.
Localized Directional Sampling
Perhaps because I had started with a Rapidly Exploring Random Tree, my brain had been pigeonholed into thinking about proximity to the exclusion of everything else. The previous algorithms had all been about using proximity to do things, like figure out whether a new point should be considered, or which point to start from when trying to get to a new target point.
But after thinking about the problem for a while, I came to realize is that everything falls more neatly into place if you think in terms of directionality as well as proximity. While obvious in hindsight, if you’ve worked on these sorts of problems before, you know it’s easy to get trapped in one way of thinking for a while and not see the bigger picture, even if it turns out to be a simple one. That is precisely what had happened to me.
Once I shifted perspective, the correct sampling behavior was obvious. Each time I wanted to expand the exploration from a point, I would do a proximity query for a local neighborhood of existing nearby points. Instead of using the distance to those points to guide the exploration, however, I would categorize them by their direction (currently, I just use the eight cardinal directions, but I’d like to experiment with different kernels here).
In any direction where I don’t “see” a point, I walk a predetermined distance and add a point wherever I end up (whether I hit something or not). In any direction where I do see a point, I walk there and make sure I can get to it. If I can, I just add a visible edge, so it’s easy for the user to see that we’re connected. If I can’t, then I do add a new point at the collision, revealing the obstacle boundary.
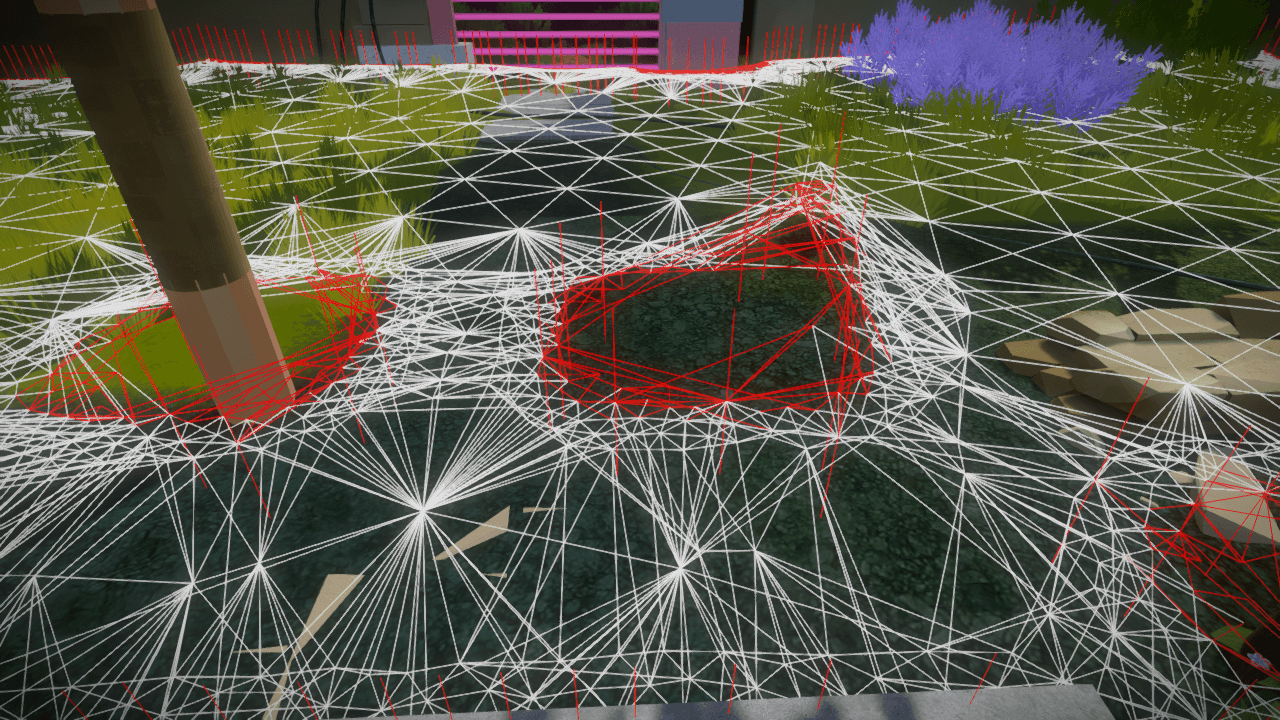
This sampling method works beautifully. It allows you to very accurately control the sampling with nicely tunable parameters, keeping all the points you want while preventing unnecessary tesselation, which leads to a very fast filling of the space:

Because it searches along directions rather than just using proximity, it is immune to boundary echo, and restricts oversampling to the boundaries where you actually want it:

Furthermore, it’s completely impervious to state changes or complex manifold problems. It deals strictly with points and those points can be anywhere, and you can add new ones at any time. If you’ve already made a map of an area with a door closed, and you open the door, all you have to do is plant a single new exploration point on the other side of the door and say “continue expanding this map”, and it’ll connect itself back up and explore the entire area beyond the door properly.
You can also change any of the core parameters at any time, and everything still works. Want to sample an area more densely? Just set the default spacing lower. You can do this in the middle of a map build, and it will start sampling more densely, with no need to jettison the existing results (which may have taken some time to produce).
Rudimentary Edge Probing
Although the algorithm by default will already sample boundaries more thoroughly, because intersections produce additional points beyond the sampling pattern, it didn’t necessarily probe them as thoroughly as I wanted, because it doesn’t do anything special when it encounters obstacles. It occurred to me that since I know which points were produced from collisions and which were not, whenever two collision points found themselves connected by an edge, I could choose to invoke extra sampling to try to find more boundary points nearby.
I haven’t yet worked on this extensively, but I put in a rudimentary method to test the theory, and it shows promise. For any two collision points connected by an edge, I step to the midpoint of the edge and probe outwards perpendicular to the edge. If I don’t collide with the boundary within a very short distance, I assume that the boundary is more complex, and add a new target there so the search will continue in that area.
Even this simple scheme produces nicely dense sampling along the boundary, without any oversampling of open regions nearby. Here’s a region with several boundaries, but without edge probing:

Now here’s the same region with edge probing:

As pleased as I am with this, I’d be surprised if there weren’t significantly better algorithms for sampling the boundary, and I look forward to trying a few more methods in the future.
Early Victories
Even with little development time, and the resulting rather simplistic code, Walk Monster already produces very usable output that can find real problems in the game. Here are just a few examples of problems I’ve noticed in passing while developing the algorithm:
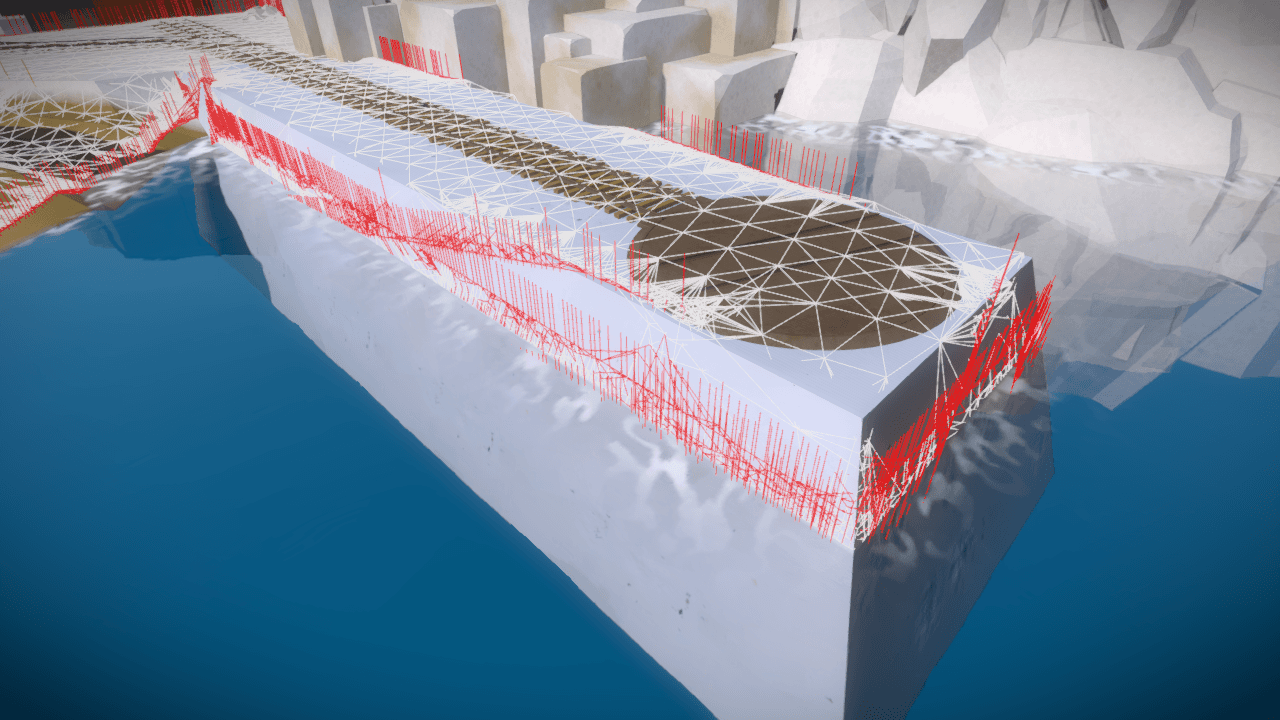
The slopes on the side of this extended platform should not have been walkable, but they were. This was because the player movement code has a pathologically bad way in which it deals with sloping geometry. I now know that’s in there, and I’ll be sure to fix it when the time comes to bulletproof it.
The Witness is meant to be a contemplative game, but wondering why there seemed to be a rock where there was no rock was not meant to be one of its koans. As you might guess, this was because someone left a collision volume in the game when the geometry it represented had already been removed. This is an easy thing to have happen, and it’s nice to have a tool that trivially reveals these mistakes quickly so people don’t have to worry about it.


These were supposed to be impenetrable rocks, but Walk Monster revealed them to be anything but. What’s worse, Walk Monster revealed that the path was somehow only traversible in one direction (from left to right in this top-down screenshot), which is never supposed to happen. I haven’t actually looked at this problem yet, besides verifying that I could actually do it via player motion (I could). It’ll be interesting to see what’s going on!
Open Questions
It’s encouraging to already have good results upon which we can build. Like I said, if you pick the right name for your source files, it all flows smoothly from there! But all of this work was done in the span of a few days, so it is obviously far from comprehensive and at lot of things are still completely ad hoc. If I have time to develop these systems further, there are a number of questions worth answering.
First, what kinds of post-processing on the data should I do to make it easiest to visualize? Drawing the raw network of points and edges can be very difficult for people to visually untangle, and some sort of better representation might make it possible for people to quickly understand more complex walkable areas at a glance.
Second, how can I improve the sampling patterns around boundaries to ensure that I find the most number of holes? Are there good methods for characterizing the ways in which shapes fall into a lattice, and are there good tessellation schemes that maximize the chances of intersecting and passing through these shapes?
Third, are regular sampling patterns or randomized sampling patterns better for filling spaces? I could easily modify the target point selection criteria to produce randomized patterns, but it’s not clear if this is worthwhile or, if it is, what kind of randomized patterns would be best.
Fourth, what other information would we like to get from our walkable area maps, now that we can build them? For example, it would be a straightforward extension of the existing system to do things like pathfinding or distance mapping, where a user could pick a point and ask for the shortest path between it and some other point, or to see a heat map of the distance between that point and all other points in the map. Are queries like this useful? What other queries might be?
For now, the walkable area visualizations we’re already getting from Walk Monster are more than enough to show us that the player movement code is pretty broken. I had planned to move on to creating a system for overnight testing via the user input method, but it seems clear that we already have enough problems to fix that there’s no need for that yet. So my next order of business, before improving these tools any further, will be to see what I can do to make the player movement code more robust. While I’m at it, I’d also like to see if I can get it an order of magnitude faster or two, because currently, the thing that slows down Walk Monster rather severely is the slow speed of the collision system.
With luck, I’ll report back soon in another installment on how that work is going.